 I quit my job in the pharmaceutical industry in 2011 to found 100Plus because I think technology will have a greater impact on improving people’s health than any new drug I could have worked on. It is still very early in the digital health revolution, and it remains to be seen which areas of digital health will find consumer adoption and successful payment models. However, there are now a few digital health companies emerging that are addressing areas of unmet medical need, focusing on key health outcomes measures and generating preliminary data on efficacy and cost effectiveness. In this sense, they are beginning to look a lot like early biotech companies.
I quit my job in the pharmaceutical industry in 2011 to found 100Plus because I think technology will have a greater impact on improving people’s health than any new drug I could have worked on. It is still very early in the digital health revolution, and it remains to be seen which areas of digital health will find consumer adoption and successful payment models. However, there are now a few digital health companies emerging that are addressing areas of unmet medical need, focusing on key health outcomes measures and generating preliminary data on efficacy and cost effectiveness. In this sense, they are beginning to look a lot like early biotech companies.
I tend to think of digital health companies on a simplistic 2-axis framework of target population (from healthy to managing chronic disease) and payment type (from traditional (payers and employers) to direct consumer payment).
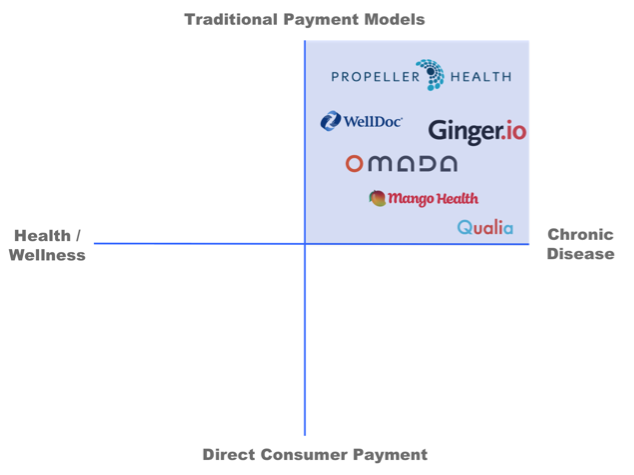
The companies focusing on specific chronic conditions and traditional payer models are the ones who are starting to look like early biotech companies and will follow a similar trajectory if successful.
Pharma industry primer
When most people think of how the pharmaceutical industry works they think of chemistry and biology. Pharma companies study the underlying biology of different diseases, then develop therapeutics (small molecules or larger proteins) to change some step in the disease process and improve the underlying diseased physiology. In my experience this is only one of the core competencies of most pharma companies and is actually a diminishing focus. The rapid rise in biotech companies over the last two decades, who ultimately partner or sell to big pharma is proof of Pharma’s diminishing reliance on this competency. Big Pharma companies have become mature distribution channels for medical products. Biotech companies serve as outsourced R&D and pharma companies essentially option them around Phase 2 (with proof-of-concept data established).
Thinking broadly, the art of drug development is more about data than chemistry. A marketed drug is actually a compound (or protein) surrounded by a robust data package. While drug development and commercialization starts with chemistry and biology, the real competency of pharma is generating a data package (pre-clinical, pharmacokinetics, pharmacodynamics, clinical efficacy, clinical safety, outcomes, etc) that facilitates approval, marketing and reimbursement for the drug. A modern day big pharma company is more adept at designing and executing clinical studies, gaining FDA approvals, gaining reimbursement from payers, marketing to physicians and distributing to pharmacies, than chemistry or biology.
Digital health as the next biotech
Most successful biotechnology companies have a core expertise in some underlying science and use that expertise to generate therapeutic candidates; most, but not all, generally focus on one therapeutic indication (like type 2 diabetes). They begin to generate data on their candidates to show safety and efficacy. If the data look promising, they partner with a Big Pharma company (around Phase 2) to help design and execute late-stage clinical programs, plan for FDA approval, plan reimbursement strategy and marketing strategy. They get an upfront payment and a share of revenue, but generally turn the reigns over to Big Pharma.
Now lets substitute an app for the molecule in the example above. Create an app that is focused on improving HbA1c in type 2 diabetics, begin to generate clinical data that the app is safe and effective, distribute through physicians and seek reimbursement for the product via traditional payors. This is WellDoc, a digital health company based in Baltimore.
There is a group of digital health companies who are beginning to follow a traditional biotech model: therapeutic focus, generating clinical data via randomized clinical trials, distributing via physicians and seeking reimbursement based on pharmacoeconomic data. WellDoc is focused on type 2 diabetes, has done a clinical trial demonstrating a 1.2% reduction in HbA1c (over usual care) and has recently launched a prescription-only app with limited reimbursement. Propeller Health, focused on respiratory diseases, has a 500 patient trial ongoing to prove efficacy and cost-effectiveness, has a dozen paying commercial programs (with a mix of payers, integrated health systems and at-risk medical groups) and will distribute through physicians. Ginger.io is working with physicians to manage a number of therapeutic areas including depression and diabetes, and has pilots ongoing to generate data on outcomes. Omada Health has run a study comparing their program outcomes to those typically seen in face-to-face versions of lifestyle programs for pre-diabetics, and is actively being paid by traditional payers. Finally, Qualia Health, a new startup out of the University of Chicago (my business school alma mater) is taking this same approach in Chronic Heart Failure.
In the future, it should not matter to pharmaceutical companies, payers, physicians or patients whether an intervention for a specific disease is chemical or technological. The only thing that matters is whether the data package generated on that intervention proves it is efficacious, safe and cost-effective over the long term (meaning patients have to use it long-term). In the near term I believe we will see pharma companies begin to embrace these new technologies and work with these companies to develop robust data packages for approval and reimbursement, then distribute them via their existing massive sales organizations. This may create a viable distribution option for many disease-focused digital health products. This also creates an opportunity for a few early companies to try to build the next generation of pharma company – fully integrated, data driven, reimbursement focused with both development, marketing and sales. But these companies will develop technology instead of chemistry.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}